
Data artist and software developer Eric Fischer, who used to work as an engineer on Google’s Android team, put together an amazing mapping project. Using Twitter’s public API he collected every geotagged tweet sent in the past three and a half years. Twitter API allows to get access to maximum a few days worth data, therefore Eric has been compressing and saving all the data in JSON format creating a repository of tweets weighting 3 terabytes and growing 4 gigabytes a day. In total he gathered 6,341,973,478 of geotagged tweets . Than he used the Mapbox API to visualize all these data points on a map.
Ultimately, only nine percent of the six billion tweets were represented as dots on the map. This is due to filtering that removed duplicate coordinates, mapping unique latitude and longitudes only once on the map:
For instance, every Foursquare check-in to a particular venue is tagged with the same location, and it doesn’t help the map to draw that same dot over and over. Showing the same person tweeting many times within a few hundred feet also makes the map very splotchy, so I filter out those near-duplicates too.
The whole process behind the project is described in Eric’s blog post.
Now let’s compare the tweet map with population density map. The conclusion is simple where there are large concentration of people and money there is higher density of tweets. When you look at India and China (where Twitter is banned) the map is practically blank. On the other hand we’ve got Brazil and Argentina with huge usage of Twitter compared even with Germany.
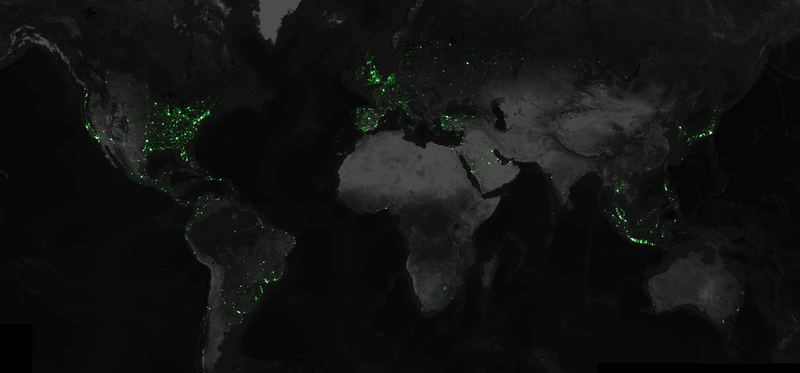
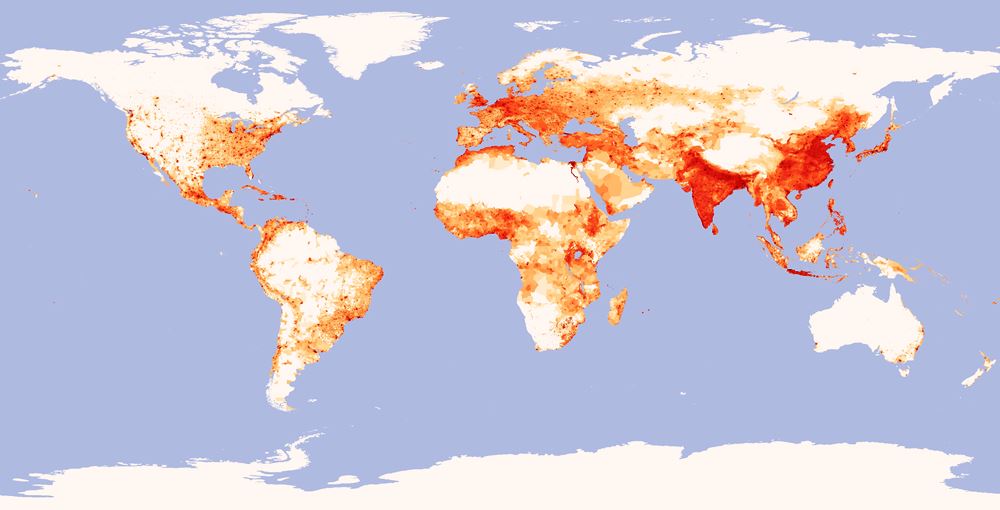
source: Mapbox

#Featured


Next article


The ESA App Camp is inviting developers to Barcelona from 25 Feb – 3 Mar 2015 for an event set to culminate in an awards ceremony at the Mobile World Congress. The participants will be selected at six simultaneous Appathons across Europe on 24-25 Jan.
From space, our planet’s atmosphere, land, and water can be monitored for multiple application fields. This is where the ESA App Camp comes in: It challenges developers to create innovative applications that will make Earth observation data accessible to a broad audience and create value in the process. Participants in Barcelona will have access to the SAP HANA Cloud Platform that enables developers to build, extend, and run applications on SAP HANA in the cloud. With its unmatched capability to process big data in high speed and its built-in geospatial functionality, it is the natural choice for running earth observation applications. Experience in integrating such data or using the SAP HANA Cloud Platform is not required to participate in the preceding Appathons.
STEP ONE – JOIN APPATHONS ACROSS EUROPE
Anyone who is up for the challenge and wants to win an invitation to the ESA App Camp Barcelona is welcome to attend one of the six Appathons. These events, which will be held at ESA Business Incubation Centres (ESA BICs) and partner locations, will offer developers the chance to meet with like-minded people and tackle some of the world’s greatest challenges. In short workshops, participants will gain insights into the SAP HANA Cloud Platform, the Earth observation programme Copernicus, and a dedicated map API. They will also have the opportunity to obtain business support from the ESA BICs and the SAP Startup Focus Programme.
Meanwhile, five challenges will inspire the participants to create the solutions of tomorrow. They will be organised into teams tasked with devising innovative application ideas and viable business cases in one of the following topic areas: Big Geo Data, Crowdsourcing Solutions, Environmental Protection, Food Security, or the Internet of Things.
A welcome package, food, and beverages will be provided. From students and professionals to company founders and freelancers, people of all skill levels are invited to participate. All developers need to bring along is a laptop and their next big idea.
The Appathons are free to attend, but participants must register on a first come, first served basis at www.app-camp.eu.
STEP TWO – WORK HARD AND IMPRESS THE JURY
After spending two days on development, each team will pitch its own innovative concept to a jury of experts. The winning team of each Appathon will then be invited to the ESA App Camp Barcelona (with all costs covered) to compete for the grand prize, which will be awarded at the Mobile World Congress 2015.
STEP THREE – GET INVITED TO THE ESA APP CAMP BARCELONA
In vying against one another for five days in the Catalan capital, the Appathon-winning teams are sure to have plenty of fun while learning a lot. Two cash prizes worth EUR 5,000 each are waiting to be presented directly at the Mobile World Congress, which all ESA App Camp participants will receive tickets to attend.
SCHEDULE
1 Dec 2014 – 19 Jan 2015 Sign up for Appathons across Europe
24 – 25 Jan 2015 Appathons at six ESA BIC and partner locations
25 Feb – 3 Mar 2015 ESA App Camp 2015, Barcelona
2 Mar 2015 Awards Ceremony on the SAP stage at the Mobile World Congress